近日,人工智能學(xué)院“人工智能與安全團隊”在大模型安全方面又取得新的研究進展,相關(guān)成果《A Multimodal Adversarial Attack Method via Frequency Domain Enhancement and Fine-Grained Cross-Modal Guidance》在線發(fā)表于IEEE Transactions on Dependable and Secure Computing (TDSC)。錢亞冠教授為第一作者,鮑琦琦博士和哈爾濱工業(yè)大學(xué)顧釗銓教授為通訊作者。
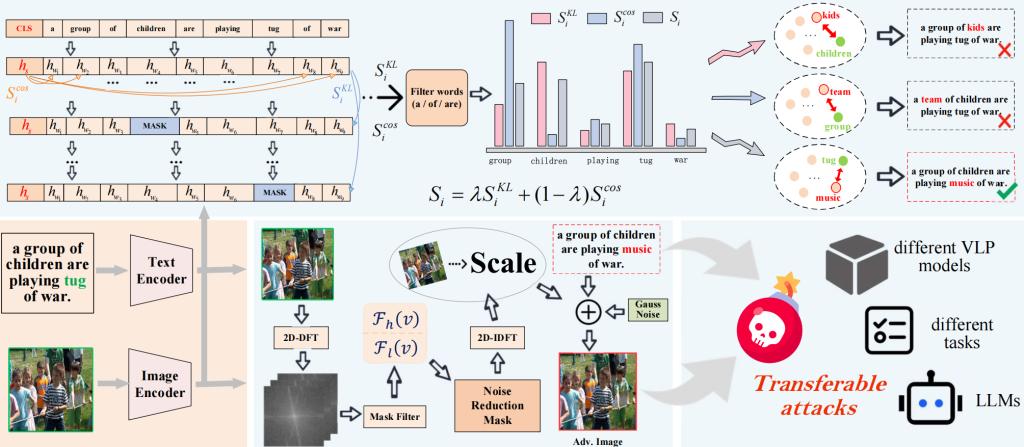
視覺-語言預(yù)訓(xùn)練(Vision-language pretraining, VLP)模型在圖文理解任務(wù)中展現(xiàn)出卓越性能,但仍極易受到可遷移對抗性攻擊的影響。針對其局限性,論文提出一種基于頻域調(diào)整的對抗性攻擊方法。此外,研究還引入細粒度特征提取技術(shù),用于優(yōu)化圖文對齊,進一步提升跨模態(tài)攻擊的可遷移性。實驗結(jié)果表明,在 Flickr30K 和 MSCOCO 數(shù)據(jù)集上,針對融合模型(fusion models)與對齊模型(alignment models)這兩大 VLP 架構(gòu),以及多個任務(wù)的測試中,所提方法均實現(xiàn)了更優(yōu)異的攻擊可遷移性與泛化性能。
TDSC是中國人工智能學(xué)會(CAAI)、中國計算機學(xué)會(CCF)共同推薦的A類期刊,在網(wǎng)絡(luò)安全領(lǐng)域享有極高的學(xué)術(shù)聲譽。本研究工作得到了國家重點研發(fā)計劃項目、國家自然科學(xué)基金面上項目、浙江省自然科學(xué)基金重點項目等的資助。(人工智能學(xué)院 袁園)


